বিক্ষেপ চিত্র (scatter plot) এমনিতেই দারুণ। নতুন করে একে আবার দারুণ বলার আসলে হয়ত খুব বেশি কারণ নেই। কিন্তু আবার আছে।
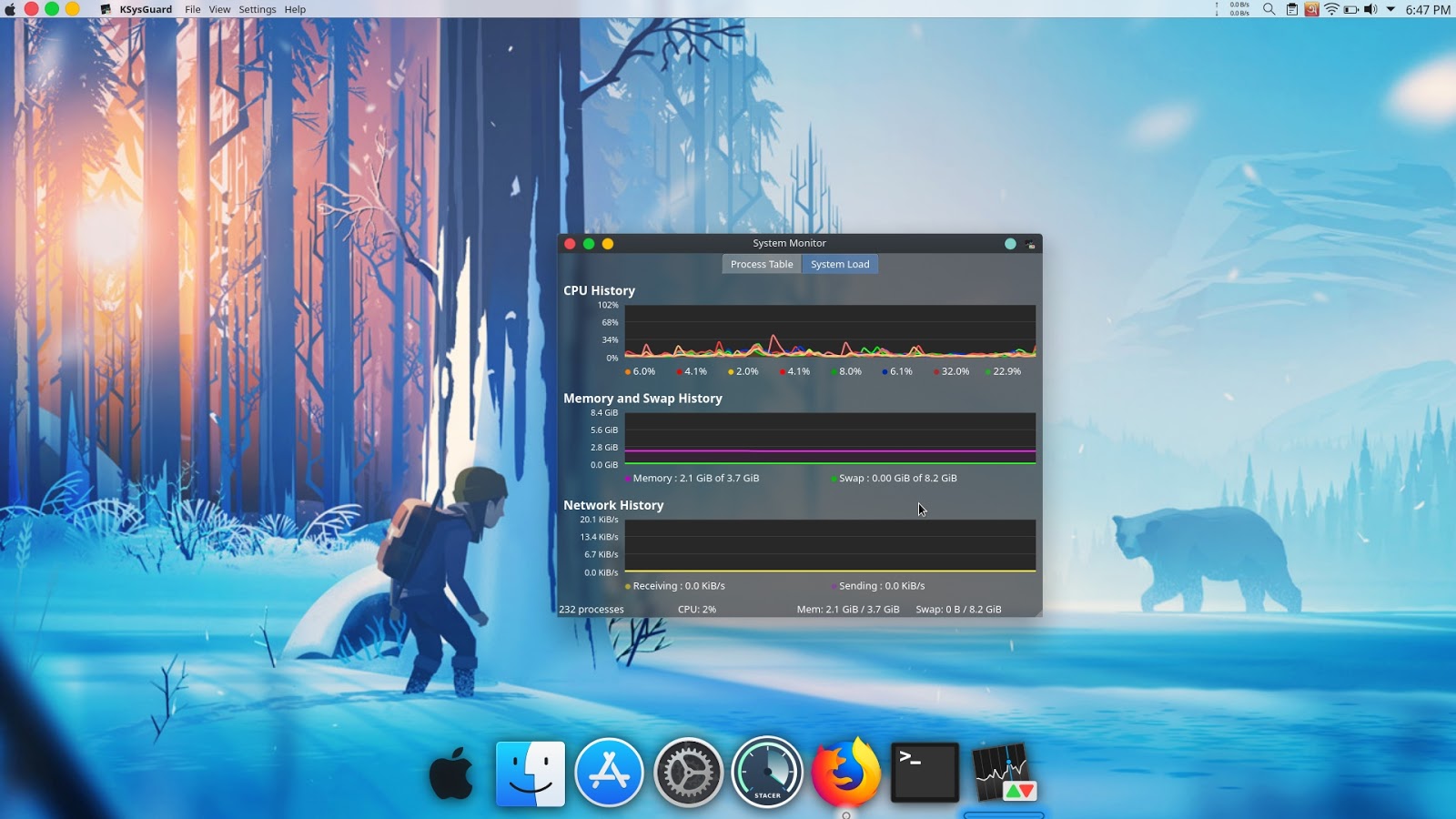
বিক্ষেপ চিত্রের মাধ্যমে আমরা দুটো সংখ্যাবাচক চলকের (quantitative variable) মধ্যে সম্পর্ক বুঝতে পারি। যেমন নীচের বিক্ষেপ চিত্রটাই দেখুন, এখানে টেস্ট ক্রিকেট খেলা দলগুলোর জেতা ও হারা ম্যাচের সংখ্যা দেখানো আছে।
দেখে বোঝা যাচ্ছে জেতা ম্যাচের সঙ্গে একটি ধনাত্মক সম্পর্ক আছে। যারা বেশি ম্যাচ জিতেছে, তারা আবার হেরেছেও বেশি। তাহলে এর মানে দাঁড়ালটা কী? আসলে এর মানে হলো, প্রায় সব দলের ক্ষেত্রেই হারা ও জেতা ম্যাচের সংখ্যা সমান। তবে দুটি দলের ক্ষেত্রে জেতা ম্যাচ মাত্র কয়েকটি, কিন্তু হারা ম্যাচের সংখ্যা প্রায় ১০০। এরা নিঃসন্দেহে অধারবাহিক দল। আরও রাখটাক করে বললে, খারাপ দল।
কিন্তু এই বিক্ষেপ চিত্র থেকে চাইল আরও বেশি তথ্য পাওয়া যায়। সেটা খুবই দারুণ। তবে আগে এই প্লটের কোডটাই দেখেই নেই।
এবার একই চিত্রটিকে আমরা ভিন্ন দৃষ্টিকোণ থেকে দেখি।



বিক্ষেপ চিত্রের মাধ্যমে আমরা দুটো সংখ্যাবাচক চলকের (quantitative variable) মধ্যে সম্পর্ক বুঝতে পারি। যেমন নীচের বিক্ষেপ চিত্রটাই দেখুন, এখানে টেস্ট ক্রিকেট খেলা দলগুলোর জেতা ও হারা ম্যাচের সংখ্যা দেখানো আছে।
 |
| টেস্ট-খেলুড়ে দলগুলোর হারা-জেতা ম্যাচের সংখ্যা |
কিন্তু এই বিক্ষেপ চিত্র থেকে চাইল আরও বেশি তথ্য পাওয়া যায়। সেটা খুবই দারুণ। তবে আগে এই প্লটের কোডটাই দেখেই নেই।
এই প্লটের কোড খুব সাধারণ। ও আচ্ছা। আমরা আজ বিক্ষেপ চিত্র আঁকব ggplot2 দিয়ে। তাই এটা লোড করতে ভুলবেন না যেন! তবে আগে ডেটা রেডি করে নেই। ডেটা পেয়েছি উইকপিডিয়ার এই পেইজ থেকে। ডেটাফ্রেইম বানাতে আমরা ব্যবহার করেছি tibble প্যাকেজ। চাইলে আপনি tibble এর জায়গায় data.frame ফাংশনও ব্যবহার করতে পারেন।
এবার আমরা আঁকার কাজটা করে ফেলি। মূল কোড কিন্তু প্রথম দুই লাইনই। পরের দুই লাইন দিয়ে লিজেন্ড সরিয়েছি, আর টাইটেল যোগ করেছি।
এখানে %>% কে বলা হয় পাইপ অপারেটর। চাইল আপনি test_win %>% ggplot অংশটুকুকে এভাবেও লিখতে পারেন।
এবার আমরা আঁকার কাজটা করে ফেলি। মূল কোড কিন্তু প্রথম দুই লাইনই। পরের দুই লাইন দিয়ে লিজেন্ড সরিয়েছি, আর টাইটেল যোগ করেছি।
এখানে %>% কে বলা হয় পাইপ অপারেটর। চাইল আপনি test_win %>% ggplot অংশটুকুকে এভাবেও লিখতে পারেন।
এবার একই চিত্রটিকে আমরা ভিন্ন দৃষ্টিকোণ থেকে দেখি।

এবার আমরা খুব সহজে নির্দিষ্ট দেশের হারা ও জেতা ম্যাচের তুলনা করতে পারছি। যেমন জিম্বাবুয়ের পরিসংখ্যান দেখুন। জেতা ম্যাচের সংখ্যা গুটিকয়েক। কিন্তু হারা ম্যাচের সংখ্যা সে তুলনায় অনেক বেশি। প্রায় ৭০। বাংলাদেশের অবস্থা তো আরও খারাপ। পাকিস্তান ও দক্ষিণ আফ্রিকার হারা ও জেতার ম্যাচের সংখ্যা প্রায় সমান। তবে ভারতের কিন্তু জেতার চেয়ে হারার রেকর্ড বেশি।
বলা চলে, অস্ট্রেলিয়ার রেকর্ড সবচেয়ে ভালো। জিতেছে প্রায় ৪০০ ম্যাচে, কিন্তু হেরেছে মাত্র ২২০ এর মতো ম্যাচ (প্লট দেখে বলছি। ডেটা দেখলে তো দেখাই যাবে ২২৪ ম্যাচ)। অস্ট্রেলিয়ার চেয়ে কম ম্যাচ খেলেও বেশি হেরেছে ইংল্যান্ড। কত দারুণ তথ্য দিচ্ছে সাধারণ এক বিক্ষেপ চিত্র! কোডটা তাহলে এবার দেখে নেই।
কাজ তো শেষ। এবার আমরা চাইলে প্লটখানাকে আরও উন্নত করতে পারি। নামের সাথে পয়েন্টও দেখাতে পারি। তবে সেজন্যে geom_text কে একটু ইডিট করে পয়েন্ট থেকে একটু পাশে সরিয়ে দিতে হবে। না হলে একটি আরেকটির ওপরে পড়ায় কোনটিই ভাল দেখা যাবে না।

এটা দেখেই অনেক ভালো বোঝা যাচ্ছে। তবে ভালোর তো শেষ নেই। আপনার বস হয়তো বলতে পারি, আমি প্লটেই আসল সংখ্যাও দেখতে চাই। কে কতটা জিতল সেটাও দেখান। কী আর করা! দেখিয়েই দিন। এ সুযোগে আমরা প্লটে ডেটা সোর্সটাও দেখিয়ে দেই।

তবে এই প্লটটা আসলে বাড়াবাড়ি। তবে বস চাইলে তো আর আসলে কিছু করার নেই। বস ইজ অলওয়েজ রাইট!
[লেখাটি উৎসর্গ করলাম সহকর্মী হাসান আহমেদকে। ও-ই প্রথম এমন একটি গ্রাফের প্রস্তাব দিয়েছিল আমাকে।]